



Các hệ thống Camera giám sát thông minh (Smart Camera) đang có xu thế được triển khai rộng rãi ở nhiều địa điểm trên thế giới, đặc biệt ở các cơ sở hạ tầng công cộng hay trung tâm mua sắm. Chúng được sử dụng với nhiều mục đích khác nhau như theo dõi lượng ra vào của khách hàng, kiểm tra gian hàng, giám sát an ninh,…
Tiềm năng thị trường của Camera thông minh ngày càng được mở rộng bởi những tiến bộ công nghệ thông tin và trí tuệ nhân tạo. Giờ đây chúng được xử lý bằng các thuật toán tiên tiến và có khả năng thực hiện nhiều tác vụ chuyên sâu như: Phân tích và phát hiện đối tượng, nhận diện khuôn mặt, thống kê lưu lượng khách hàng,… Bài viết dưới đây cung cấp một số công nghệ điển hình sử dụng trong các Hệ thống Camera thông minh để mang tới các tính năng đột phá.
Công nghệ nhận diện và xác thực khuôn mặt (Face Recognition & Identification) trong camera thông minh
Hệ thống nhận dạng khuôn mặt hoạt động bằng cách ghi lại hình ảnh hai chiều hoặc ba chiều của đối tượng trên camera, tùy vào từng trường hợp cụ thể. Những dữ liệu hình ảnh này được lưu trữ trên máy chủ và tiến hành so sánh với thông tin liên quan trong cơ sở dữ liệu trong thời gian thực. Trong thuật toán sử dụng những phân tích toán học và sinh trắc học liên quan đến hình ảnh. Nhờ sử dụng trí tuệ nhân tạo (AI) và công nghệ học máy, hệ thống nhận dạng khuôn mặt có thể hoạt động với các tiêu chuẩn an toàn và độ tin cậy cao nhất.

Quy trình của công nghệ này có thể bao gồm những bước như sau:
- Tiến hành thu lại dữ liệu hình ảnh khuôn mặt từ camera (có thể là ảnh chụp tĩnh hoặc video động). Tuy nhiên các dữ liệu hình ảnh khi đối tượng nhìn về phía camera sẽ mang lại tính chính xác cao hơn.
- Phần mềm nhận dạng khuôn mặt tiến hành đọc hình dạng khuôn mặt của đối tượng. Các yếu tố chính được quan tâm bao gồm khoảng cách giữa hai mắt và khoảng cách từ trán đến cằm. Phần mềm xác định điểm mốc trên khuôn mặt, đây là chìa khóa để phân biệt khuôn mặt của các đối tượng khác nhau.
- Điểm mốc để nhận diện trên khuôn mặt của đối tượng bạn được đưa vào các thuật toán và mô hình để so sánh với cơ sở dữ liệu về các khuôn mặt có sẵn.
- Trả ra kết quả sau khi khớp khuôn mặt của đối tượng trong camera với dữ liệu khuôn mặt sẵn có trong cơ sở dữ liệu của hệ thống nhận dạng khuôn mặt.
Công nghệ chống giả mạo khuôn mặt (Face Anti-Spoofing – FAS) trong camera thông minh
Nhiều khi các hệ thống nhận diện khuôn mặt thường bị tấn công bởi các thủ thuật gian lận khác nhau, chẳng hạn như hình ảnh, video giả mạo, mặt nạ 3D và trang điểm. Công nghệ chống giả mạo khuôn mặt (FAS) đóng một vai trò quan trọng trong việc bảo mật và đảm bảo an toàn. Với thuật toán phát hiện thông minh, FAS giúp hệ thống nhận dạng khuôn mặt bảo mật tốt hơn và thu hút nhiều sự chú ý hơn từ các ngành công nghiệp khác nhau.
Một số kĩ thuật thường được áp dụng trong FAS hiện nay:
Sử dụng các tính năng học sâu (Deep Learning Features) với Mạng nơ-ron tích chập (Convolutional Neural Network – CNN)
Ở đây coi các vấn đề về chống giả mạo như một bài toán phân loại nhị phân, sử dụng huấn luyện CNN để nhận ra đâu là dữ liệu hình ảnh thật và đâu là dữ liệu hình ảnh giả mạo. Tuy nhiên, nó chỉ hoạt động với một số bộ dữ liệu nhất định trong các điều kiện cụ thể, chẳng hạn như chất lượng máy ảnh, môi trường, ánh sáng, v.v. Nếu bất kỳ điều nào trong số đó bị thay đổi – CNN sẽ không còn trả ra kết quả chính xác. Vì vậy, phương pháp này chỉ khả thi trong các trường hợp sử dụng hạn chế.
Kỹ thuật phản ứng thách thức
Kỹ thuật này sử dụng các hành động đặc trưng của con người, và coi chúng là những thách thức. Hệ thống hoạt động để xác minh rằng những thách thức đó xảy ra trong một chuỗi video được cung cấp. Hệ thống phản hồi dựa trên một loạt các thách thức đã xác định được để xác thực danh tính của một cá nhân.
Những thách thức này có thể bao gồm: Các trạng thái cười, nét mặt buồn bã hay hạnh phúc, chuyển động phần đầu.
Mặc dù mang đến nhiều hiệu quả trong việc nhận biết giả mạo nhưng phương pháp này lại yêu cầu đa dạng hơn về bộ dữ liệu đầu vào và trong một số trường hợp gây ảnh hưởng tới trải nghiệm người dùng.
Công nghệ nhận diện cảm xúc khuôn mặt trong camera thông minh
Đây là một bài toán phân lớp tương đối tiêu chuẩn, đã được nghiên cứu trong một thời gian khá dài. Một hệ thống nhận diện cảm xúc khuôn mặt thường được triển khai gồm 3 bước.
Nhận ảnh và tiền xử lý
Ảnh khuôn mặt được lấy từ nguồn dữ liệu tĩnh (chẳng hạn như từ file, database), hoặc động (từ livestream, webcam, camera,…), nguồn dữ liệu này có thể trải qua một số bước tiền xử lý nhằm tăng chất lượng hình ảnh để giúp việc phát hiện cảm xúc trở nên hiệu quả hơn.
Trích xuất các đặc trưng
Bước rất quan trọng, đặc biệt với các phương pháp truyền thống, các đặc trưng khuôn mặt được tính toán dựa trên các thuật toán có sẵn, kết quả thường là một vector đặc trưng làm đầu vào cho bước sau.
Phân lớp và nhận diện cảm xúc
Đây là một bài toán phân lớp điển hình, rất nhiều các thuật toán có thể áp dụng trong bước này như KNN (K-Nearest Neighbors), SVM (Support Vector Machine), LDA (Linear Discriminant Analysis), HMM (Hidden Markov Model),…
Các mạng học sâu được ứng dụng rộng rãi vào bài toán phát hiện cảm xúc khuôn mặt, đặc biệt các loại mạng phù hợp với việc xử lý dữ liệu hình ảnh như CNN (Convolutional Neural Network), DBN (Deep Belief Network), DAE (Deep Autoencoder).
Một số công nghệ bổ trợ khác trong camera thông minh
Ngoài ra nhờ cơ sở hạ tầng dữ liệu lớn, trí tuệ nhân tạo (AI) cùng các mô hình và thuật toán tiên tiến, ngày nay còn có nhiều công nghệ hiện đại như: Công nghệ nhận dạng độ tuổi giới tính, nhận dạng khách hàng VIP, ngăn chặn tội phạm,…
Đây đều là những sự phát triển từ hệ thống nhận diện khuôn mặt (Face Recognition). Hệ thống nhận diện khuôn mặt cho phép lưu trữ thông tin cá nhân của tất cả các đối tượng. Ngay khi nhận diện được đối tượng ra vào tòa nhà, cửa hàng, hệ thống sẽ tiến hành xử lý, phân tích độ tuổi và giới tính, trích xuất thông tin. Ngoài ra hệ thống còn tiến hành nhận diện đối tượng đáng ngờ (dựa vào cơ sở dữ liệu tội phạm), sau đó có thể báo ngay thông tin cho nhân viên bán hàng, nhà quản lý và nhân viên an ninh để có phương án xử lý kịp thời. Sử dụng nhận dạng khuôn mặt đã được chứng minh là giảm tới 91% hành vi bạo lực tại cửa hàng. Công nghệ nhận diện khuôn mặt cũng có thể xác định được hình ảnh khách hàng VIP và mã số ID của họ sau đó thông báo cho nhân viên để họ sẵn sàng tiếp đón và giúp đỡ.
Các hệ thống Camera thông minh ngày nay không chỉ giúp cho các doanh nghiệp có thể đảm bảo an ninh, thực hiện giám sát, mà còn góp phần thu thập thông tin khách hàng, tiền xử lý dữ liệu, phát hiện khách hàng VIP, khách hàng trung thành và cải thiện các phương án kinh doanh. Camera thông minh sẽ còn phát triển nhiều hơn nữa trong tương lai, khi ứng dụng của trí tuệ nhân tạo (AI) và các thuật toán học sâu (Deep Learning) đang được nghiên cứu và cải tiến từng ngày.
| Hiện tại, giải pháp Camera thông minh là một trong những sản phẩm mũi nhọn tại VinBigData – VinCamAI. Được phát triển dựa trên trí tuệ nhân tạo (AI) và các công nghệ lõi hàng đầu, VinCamAI mang đến nhiều tính năng nổi bật như: Nhận diện người ngay cả khi đang đeo khẩu trang với độ chính xác cao (>=90%); nhận diện, phân tích và thống kê người, vật thể với kết quả chính xác tới 95%, hoạt động chính xác hơn hệ thống Camera truyền thống từ 17-25%,… Tìm hiểu thêm về VinCamAI: Tại đây |
Tư liệu tham khảo: Towards Data Science
Trong Thị giác máy tính, phân vùng ảnh là một kỹ thuật quan trọng, giúp giải nhiều bài toán thuộc các lĩnh vực khác nhau như xử lý ảnh y tế, phát hiện và nhận dạng đối tượng, hệ thống camera thông minh… Đây là tiền đề của quá trình xử lý dữ liệu hình ảnh. Kết quả phân vùng tốt sẽ tạo điều kiện thuận lợi cho các khâu xử lý về sau, đảm bảo tính hiệu quả cao, gia tăng mức độ chính xác, đồng thời giảm thiểu nguồn lực tính toán.
Phân vùng ảnh là gì?
Phân vùng ảnh (Image segmentation) là một phương pháp mà trong đó, hình ảnh kỹ thuật số được chia thành nhiều nhóm con khác nhau được gọi là segments. Mục tiêu của phân vùng ảnh là làm giảm độ phức tạp của hình ảnh, giúp cho quá trình xử lý hoặc phân tích hình ảnh sau đó trở nên đơn giản hơn. Nói một cách dễ hiểu, phân vùng là dán nhãn cho từng pixel. Tất cả các yếu tố hình ảnh hoặc pixel thuộc cùng một danh mục sẽ có chung một nhãn. Ví dụ: Đối với bài toán phát hiện đối tượng, thay vì xử lý toàn bộ hình ảnh, máy có thể chỉ thực hiện trên một đoạn được chọn bởi thuật toán phân vùng. Điều này sẽ ngăn máy xử lý toàn bộ hình ảnh, do đó làm giảm thời gian suy luận.

Các cách tiếp cận phân vùng ảnh
- Cách tiếp cận tương đồng (Similarity approach), có nghĩa là phát hiện sự tương đồng giữa các pixel hình ảnh để tạo thành một phân đoạn, dựa trên một ngưỡng. Các thuật toán học máy như phân cụm thường dựa trên kiểu tiếp cận này để phân vùng một hình ảnh.
- Cách tiếp cận gián đoạn (Discontinuity approach): Cách tiếp cận này dựa trên sự gián đoạn của các giá trị cường độ pixel trong hình ảnh. Các kỹ thuật phát hiện đường, điểm và cạnh sử dụng kiểu tiếp cận gián đoạn để thu được các kết quả phân vùng trung gian. Kết quả này sau đó có thể được xử lý để cho ra hình ảnh được phân vùng cuối cùng.
Một số kỹ thuật phân vùng ảnh
Có 05 kỹ thuật phân vùng ảnh, bao gồm:
- Phân vùng dựa trên ngưỡng (Threshold Based Segmentation)
- Phân vùng dựa trên cạnh (Edge Based Segmentation)
- Phân vùng dựa trên khu vực (Region-Based Segmentation)
- Phân vùng dựa trên kỹ thuật phân cụm (Clustering Based Segmentation)
- Phân vùng dựa trên mạng nơron nhân tạo (Artificial Neural Network Based Segmentation)
Dưới đây là những thông tin cụ thể về từng loại kỹ thuật phân vùng này.
1, Phân vùng dựa trên ngưỡng (Threshold Based Segmentation)
Phân đoạn ngưỡng ảnh là một dạng phân vùng ảnh đơn giản, giúp tạo ra một hình ảnh nhị phân hoặc nhiều màu dựa trên việc đặt giá trị ngưỡng theo cường độ pixel của hình ảnh gốc.
Trong quá trình xác định ngưỡng, cần xem xét biểu đồ cường độ của tất cả các pixel trong hình ảnh. Sau đó, tiến hành đặt một ngưỡng để chia hình ảnh thành các phần. Ví dụ: khi xem xét các pixel hình ảnh nằm trong khoảng từ 0 đến 255, ngưỡng có thể đặt là 60. Vì vậy, tất cả các pixel có giá trị nhỏ hơn hoặc bằng 60 sẽ được cung cấp giá trị 0 (màu đen) và tất cả các pixel có giá trị lớn hơn hơn 60 sẽ được cung cấp với giá trị 255 (màu trắng).
Đối với một ảnh có nền và đối tượng, có thể chia ảnh thành các vùng dựa trên cường độ của đối tượng và nền. Nhưng ngưỡng này phải được thiết lập hoàn hảo để phân đoạn hình ảnh thành một đối tượng và một nền.
Phân ngưỡng bao gồm các kỹ thuật như ngưỡng toàn cục (Global thresholding); ngưỡng thủ công (Manual thresholding); ngưỡng thích ứng (Adaptive Thresholding); ngưỡng tối ưu (Optimal Thresholding); ngưỡng thích ứng cục bộ (Local Adaptive Thresholding).
2, Phân vùng dựa trên cạnh (Edge Based Segmentation)
Cạnh trong ảnh đánh dấu những vị trí hình ảnh không liên tục về mức xám, màu sắc, kết cấu, v.v. Khi di chuyển từ vùng này sang vùng khác, mức xám có thể thay đổi. Vì vậy, nếu tìm thấy sự gián đoạn đó, ta có thể tìm thấy cạnh. Thực tế, có nhiều toán tử phát hiện cạnh, nhưng hình ảnh thu được là kết quả phân vùng trung gian, và không nên nhầm lẫn với hình ảnh được phân vùng cuối cùng. Để ra được kết quả cuối, cần thực hiện một số bước bổ sung bao gồm: kết hợp các phân vùng cạnh thu được làm một, để giảm số lượng phân vùng và có được một đường viền liền mạch của đối tượng.
Như vậy, có thể thấy, phân vùng cạnh đưa ra một kết quả phân vùng trung gian. Kết quả này sau đó có thể áp dụng theo vùng hoặc bất kỳ kiểu phân đoạn nào khác, nhằm có được hình ảnh được phân vùng cuối.

Các cạnh thường được liên kết với “Độ lớn” và “Hướng”. Một số toán tử phát hiện cạnh cung cấp cả hai yếu tố này, chẳng hạn như Sobel edge operator, canny edge detector, Kirsch edge operator, Prewitt edge operator, Robert’s edge operator,….
3, Phân vùng dựa trên khu vực (Region-Based Segmentation)
Một vùng có thể được phân loại là một nhóm các pixel kết nối với nhau và có các thuộc tính tương đồng về cường độ, màu sắc, v.v. Trong kiểu phân vùng này, có một số quy tắc được định sẵn mà pixel phải tuân theo để đảm bảo có thể phân loại thành các vùng pixel tương tự. Phương pháp phân vùng dựa trên khu vực được ưu tiên hơn phương pháp phân vùng dựa trên cạnh trong trường hợp ảnh bị nhiễu.
Có 2 nhóm kỹ thuật chính trong phân vùng dựa trên khu vực, bao gồm:
- Phát triển khu vực (Region growing method)
- Phân tách và hợp nhất khu vực (Region splitting and merging method)
Phát triển khu vực (Region growing method)
Đối với kỹ thuật này, chúng ta bắt đầu với một số pixel làm pixel hạt giống và sau đó kiểm tra các pixel liền kề. Nếu các pixel liền kề tuân theo các quy tắc được xác định trước, thì pixel đó sẽ được thêm vào vùng của pixel gốc và quá trình sẽ tiếp tục cho đến khi không còn điểm tương đồng nào. Phương pháp này thực hiện theo cách tiếp cận từ dưới lên. Trong trường hợp khu vực đang phát triển, quy tắc ưu tiên có thể được đặt làm ngưỡng.
Phân tách và hợp nhất khu vực
Đối với phân tách khu vực, toàn bộ hình ảnh đầu tiên được chụp dưới dạng một vùng duy nhất. Nếu không tuân theo các quy tắc được xác định trước, vùng đó sẽ lại được chia thành nhiều vùng (thường là 4 góc phần tư) và tiếp tục áp dụng các quy tắc để quyết định có chia nhỏ hơn nữa hay không. Quá trình này kéo dài cho đến khi không có sự phân chia khu vực nào nữa, tức là mọi khu vực đều tuân theo các quy tắc được xác định trước.
Điều kiện kiểm tra để quyết định có nên chia nhỏ một vùng hay không là: Nếu giá trị tuyệt đối của sự chênh lệch giữa cường độ pixel tối đa và tối thiểu trong một vùng nhỏ hơn hoặc bằng một giá trị ngưỡng do người dùng quyết định thì vùng đó không yêu cầu chia nhỏ thêm.

Đối với hợp nhất khu vực, mỗi pixel được coi là một vùng riêng lẻ. Ta chọn một vùng làm vùng hạt giống để kiểm tra tính tương đồng của các vùng lân cận dựa trên quy tắc được định trước. Nếu giống nhau, chúng sẽ được hợp nhất thành một vùng duy nhất và cứ tiếp tục như vậy cho đến khi xây dựng các vùng được phân đoạn của toàn bộ hình ảnh.
Cả phân tách và hợp nhất khu vực đều là quá trình lặp đi lặp lại. Thông thường, việc tách vùng đầu tiên được thực hiện trên một hình ảnh để chia ảnh đó thành các vùng tối đa, trước khi các vùng này được hợp nhất để tạo thành hình ảnh mới, với những phân vùng tốt hơn so với hình ảnh gốc.
4, Phân vùng dựa trên kỹ thuật phân cụm (Clustering Based Segmentation)
Phân cụm (Clustering) là một loại thuật toán học máy không giám sát, được sử dụng phổ biến trong phân vùng ảnh. Một trong những thuật toán Clustering thường được ứng dụng cho tác vụ phân vùng ảnh là KMeans Clustering. Loại phân cụm này có thể được sử dụng để tạo các phân đoạn trong một hình ảnh có màu.
KMeans Clustering
Hãy hình dung về một tập dữ liệu 2 chiều. Đầu tiên, trong tập dữ liệu, các trọng tâm – centroid (do người dùng chọn) được khởi tạo ngẫu nhiên. Sau đó, tiến hành tính toán khoảng cách của tất cả các điểm đến tất cả các cụm. Điểm được gán cho cụm có khoảng cách nhỏ nhất. Tiếp đến, trọng tâm của tất cả các cụm được tính toán lại bằng cách lấy giá trị trung bình của cụm đó và các điểm dữ liệu lại một lần nữa được gán cho các cụm. Quá trình này tiếp diễn cho đến khi thuật toán hội tụ thành một giải pháp tốt. Thông thường, số lần lặp lại như vậy rất nhỏ.
5, Phân vùng dựa trên mạng nơron nhân tạo (Artificial Neural Network Based Segmentation)
Kỹ thuật này sử dụng AI để tự động phân tích một hình ảnh và xác định các thành phần khác nhau của nó như khuôn mặt, đối tượng, văn bản, v.v. Mạng thần kinh tích chập (convolutional neural networks) khá phổ biến đối với việc phân vùng ảnh vì chúng có thể xác định và xử lý dữ liệu hình ảnh một cách nhanh chóng và hiệu quả.
Các chuyên gia tại Facebook AI Research (FAIR) đã tạo ra một kiến trúc học sâu được gọi là Mask R-CNN, có thể được sử dụng như một bộ lọc pixel thông minh cho mọi đối tượng trong ảnh. Đây là phiên bản nâng cao của kiến trúc phát hiện đối tượng Faster R-CNN.
Trong quá trình phân vùng ảnh, trước tiên phải chuyển hình ảnh đầu vào đến ConvNet để tạo bản đồ đối tượng cho hình ảnh. Sau đó, hệ thống áp dụng mạng đề xuất vùng (Region Proposal Network – RPN) trên bản đồ đối tượng và tạo đề xuất đối tượng cùng với điểm số của chúng. Sau đó, lớp tổng hợp ROI (Region of interest) được triển khai cho các đề xuất để giảm chúng xuống một kích thước. Trong giai đoạn cuối cùng, hệ thống chuyển các đề xuất đến lớp kết nối để phân loại và tạo ra kết quả với các hộp giới hạn được gán cho mọi đối tượng.
| Từ các kỹ thuật phân vùng ảnh, VinBigdata phát triển các sản phẩm, giải pháp khác nhau liên quan đến công nghệ Thị giác máy tính. Trong lĩnh vực xử lý ảnh y tế, VinDr là giải pháp AI toàn diện hỗ trợ các bác sĩ chẩn đoán hình ảnh đưa ra quyết định nhanh chóng, chính xác và giảm thiểu bỏ sót tổn thương. Chỉ mất vài giây cho mỗi ca chụp, VinDr đã có thể phát hiện, khoanh vùng và phân loại đa dạng tổn thương trên phổi, vú, não, cột sống, gan mật, với độ chính xác trên 90%. Không những giải quyết bài toán về y tế, VinBigdata còn nghiên cứu, kiến tạo các sản phẩm công nghệ hỗ trợ doanh nghiệp tối ưu hóa hiệu quả sản xuất, kinh doanh. Dựa trên các công nghệ hiện đại, trong đó có công nghệ nhận diện và phân tích khuôn mặt chính xác đến 99%, VinCamAI là giải pháp camera thông minh có khả năng phát hiện và nhận diện khuôn mặt, phân tích thuộc tính khuôn mặt (độ tuổi, giới tính, cảm xúc, phụ trang), nhận diện người, phương tiện, nhận diện hành vi, theo dõi luồng di chuyển. Sản phẩm có thể được tích hợp trong các hệ thống camera thông minh hay phân tích, xác thực khách hàng tại các trung tâm thương mại, khu du lịch, nghỉ dưỡng, nhà thông minh,… |
Một trong những chìa khóa quyết định sự thành công xe tự hành nằm ở trình theo dõi đường đi (path tracker). Trên lý thuyết, tồn tại rất nhiều kỹ thuật, với các mức độ phức tạp và tính hiệu quả khác nhau trong một số tình huống cụ thể. Việc lựa chọn trình theo dõi đường đi ảnh hưởng đến hiệu suất về độ chính xác, độ ổn định và sự thoải mái của hành khách. Bài viết dưới đây sẽ giới thiệu 03 thuật toán điều khiển phổ biến cho xe tự hành, bao gồm: Pure Pursuit, Stanley và Model Predictive Controller.
Khái quát về thuật toán điều khiển/kiểm soát đường đi của xe tự hành
Ngày nay, xe tự hành nằm trong số các lĩnh vực nghiên cứu đang phát triển nhanh và quan trọng nhất của robotics. Các phương tiện tự động giúp đáp ứng việc tăng lưu lượng, mật độ, hiệu quả, an toàn và cảm giác thoải mái khi di chuyển. Nhiều giải pháp xe tự hành đã được triển khai thử nghiệm trên thế giới và ngay tại Việt Nam. Những nỗ lực nghiên cứu vẫn tiếp tục được thực hiện nhằm cải thiện hiệu suất, độ tin cậy và cắt giảm chi phí của xe tự hành.
Khả năng điều hướng tự động của xe tự hành bao gồm ba bước chính: Nhận thức và bản địa hóa – Lập kế hoạch – Kiểm soát. Trong đó, kiểm soát phương tiện là bước cuối cùng trong hệ thống điều hướng và thường được thực hiện bằng cách sử dụng một trong hai bộ điều khiển độc lập:
- Lateral Controller: Điều chỉnh góc lái sao cho xe đi theo đường tham chiếu. Bộ điều khiển giảm thiểu sai số giữa vị trí xe hiện tại và đường đi đã đươc định sẵn.
- Longitudinal Controller: Bộ điều khiển dọc giảm thiểu sự khác biệt giữa hướng của xe và hướng của đường tham chiếu. Giúp xe di chuyển một cách ổn định không bị rung lắc và tăng tốc giảm tốc mượt mà hơn.
Mục tiêu của bộ điều khiển là đảm bảo xe đi theo một con đường mong muốn bằng cách giảm thiểu sai số giữa xe và đường đi tham chiếu. Đồng thời vận tốc của xe cũng phải ổn định dựa trên đường đi tham chiếu sẽ được định trước bởi thuật toán về path planning. Lateral Controller cũng có thể được sử dụng cho các ứng dụng giữ làn đường.
03 thuật toán điều khiển ngang
1, Thuật toán Pure Pursuit
Pure Pursuit tính toán góc lái dựa trên thông tin về vị trí của xe và đường đi mà xe phải bám theo. Vận tốc của xe sẽ tùy thuộc vào đặc tính của từng khu vực (Đường trống, đường đông dân cư, đường có độ dốc lớn,…) vật cản trên đường. Sau đó, thuật toán sẽ di chuyển điểm ở phía trước trên đường đi dựa trên vị trí hiện tại của phương tiện, dần dần cho đến điểm cuối cùng. Hiểu một cách đơn giản, phương tiện liên tục đuổi theo một điểm trước mặt nó. Thuộc tính LookAheadDistance quyết định khoảng cách xác định điểm nhìn về phía trước.
controllerPurePursuit không phải là một bộ điều khiển truyền thống, mà hoạt động như một thuật toán theo dõi đường đi. Các đặc tính này được xác định dựa trên các thông số kỹ thuật của xe. Với đầu vào là vị trí, hướng của xe và đường tham chiếu có thể tính toán vận tốc và góc lái tương ứng.

2, Thuật toán Stanley Controller
Đây là phương pháp theo dõi đường đi được sử dụng bởi nhóm nghiên cứu của Đại học Stanford. Khác với phương pháp Pure Pursuit sử dụng trục sau làm điểm tham chiếu, phương pháp Stanley sử dụng trục trước làm điểm tham chiếu. Trong khi đó, nó xem xét cả (heading error and cross-track error). Trong phương pháp này, lỗi đường chéo được định nghĩa là khoảng cách giữa điểm gần nhất trên đường dẫn với trục trước của xe.
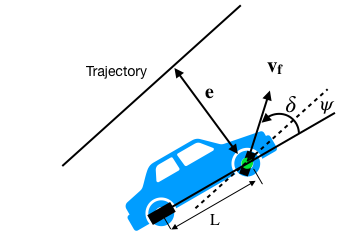
Stanley là một phương pháp đơn giản nhưng hiệu quả và ổn định cho việc điều khiển sau này. Cả Pure Pursuit và Stanley đều là những thuật toán dựa trên hình học. Dưới đây sẽ là một bộ điều khiển phi hình học khác – Bộ điều khiển dự đoán mô hình (Model Predictive Controller – MPC)
3, Thuật toán Model Predictive Controller – MPC
MPC sử dụng một mô hình của hệ thống để đưa ra dự đoán về hành vi trong tương lai của chính hệ thống đó. MPC giải quyết một thuật toán tối ưu trực tuyến (an online optimization algorithm) để tìm ra hành động điều khiển tối ưu, từ đó đưa ra kết quả dự đoán. MPC có thể xử lý các hệ thống có nhiều đầu ra, đầu vào và giữa chúng có mối liên hệ. Với khả năng dự đoán; MPC kết hợp thông tin tham chiếu trong tương lai vào bài toán điều khiển để cải thiện hiệu suất của bộ điều khiển.
Thực tế, MPC sở hữu rất nhiều lợi thế. Tuy nhiên, hạn chế của MPC là tốn kém về mặt tính toán, đặc biệt đối với những mô hình phi tuyến tính.
| VinBigdata cũng tham gia nghiên cứu, phát triển xe điện tự hành cấp độ 4, trọng tải lớn (23 chỗ). Dựa trên những công nghệ tiên tiến, xe có các tính năng tiêu biểu như định vị tối ưu, nhận diện vật cản, tự động giảm tốc, dừng hoặc chuyển làn tránh vật cản, thay đổi lộ trình khi cần thiết, đi lùi, tự động đỗ xe, chạy về trạm sạc khi hết pin…. Dự kiến, giải pháp này có thể sẽ được ứng dụng để tiếp tục phát triển các tính năng cho các dòng xe điện thông minh trong tương lai. |

